Table des matières
Références globales :
- CNP3, chap. The HyperText Transfer Protocol
- CNP3, chap. Making HTTP faster
3.3. Le World Wide Web
Le World Wide Web est un réseau de documents hébergé sur des serveurs distants. Il fonctionne selon le modèle “client/serveur” : les documents sont stockés sur des serveurs, dont le rôle consiste à répondre à des requêtes en provenance des machines clientes.
Trois éléments définissent son fonctionnement :
- Le format de document HTML
- Le système d’adressage standardisé pour identifier les documents
- Le protocole HTTP pour permettre l’échange des documents. Le protocole HTTP a évolué avec le temps, et est à présent principalement utilisé dans sa version sécurisée (HTTPS). Bien que sa version 1 ait longtemps prédominé dans l’Internet, les versions 2 et 3 sont à présent de plus en plus déployées.
Les URI
Pour pouvoir demander un document ou une ressource sur le web, il faut pouvoir l’identifier et le localiser. Pour cela, une chaîne de caractère appelée Uniform Resource Identifier est utilisée. Les URIs seront notamment utilisées dans les liens hypertextes. Leur format est défini dans le RFC 3986.
Parmi les URIs, on distingue deux types :
- Les URL (Uniform Resource Locator) qui, en plus d’identifier une ressource, indiquent comment les localiser.
- Les noms (URNs - Uniform Resource Names), qui doivent être uniques et persistants dans le temps et l’espace. Chaque URI de type nom doit identifier une ressource unique, même après que la ressource en question ait cessé d’être accessible. Par exemple, l’ISBN d’un livre est un URN (et donc un URI) pour ce livre. Il permet de l’identifier de manière non équivoque, mais ne donne pas pour autant d’information sur l’endroit où on peut se le procurer.
Un URI peut être soit un nom, soit un localisateur, soit les deux.
Le format exact et complet des URIs est complexe, et documenté dans le RFC correspondant.
Nous le détaillerons pas précisément ici, mais voici néanmoins quelques exemples d’URIs tirés du RFC. Ces exemples sont analysés dans la page Wikipédia sur les schémas d’URI.
ftp://ftp.is.co.za/rfc/rfc1808.txt
http://www.ietf.org/rfc/rfc2396.txt
ldap://[2001:db8::7]/c=GB?objectClass?one
mailto:John.Doe@example.com
news:comp.infosystems.www.servers.unix
tel:+1-816-555-1212
telnet://192.0.2.16:80/
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
urn:isbn:978-951-0-18435-6
Les URIs comportent les éléments suivants :
-
Un schéma (scheme en anglais), obligatoire, donnant un cadre d’interprétation des champs suivants. Le schéma se termine par le caractère
:. Le schéma peut être un protocole (http, ftp, ldap), mais pas que : il peut également identifier une adresse mail (mailto) ou un numéro de téléphone (tel). - Un champ d’autorité (non obligatoire): permet d’identifier l’autorité responsable de la ressource. Ce champ commence par un double slash
//, et se termine au prochain slash/, point d’interrogation?ou dièse#ou à la fin de l’URI. Il peut contenir :- Un identifiant utilisateur facultatif, suivi par un @ (ex :
http://toto@localhost) - Un hôte, identifié par son nom DNS ou adresse IPv4 ou IPv6. Les adresses IPv6 sont encadrées par des crochets pour éviter les ambiguïtés lors de l’analyse de l’URI.
- Un numéro de port facultatif, précédé par un
:(s’il n’est pas indiqué, le port par défaut du protocole indiqué dans le schéma sera utilisé le cas échéant)
- Un identifiant utilisateur facultatif, suivi par un @ (ex :
- Un chemin d’accès vers le document, obligatoire (mais éventuellement vide), formaté de manière similaire aux systèmes de fichiers UNIX. Cela n’implique pas pour autant que ce chemin d’accès représente effectivement la hiérarchie de répertoires physiques sur le serveur. Par exemple :
https://www.example.org/folder/file.txtpourrait représenter le fichier file.txt dans le répertoire folder sur le serveurwww.example.com, ou non.https://www.example.com/user/profile/ne représente probablement pas un répertoire sur le serveur, mais indique plutôt la route vers le profil de l’utilisateur courant lorsque ce dernier est connecté.
-
Le composant “query”, optionnel, indiqué par le premier caractère
?de l’URI et terminé soit par un ‘#’, soit par la fin de l’URI. Il contient des informations supplémentaires n’entrant pas dans la partie hiérarchique (autorité + path). Ces informations sont souvent représentées sous formeclé=valeur. Par exemple :https://www.example.com/user/profile?lang=frpermet d’indiquer que la page souhaitée doit être affichée en français. - Le fragment, débutant par un dièse
#, indique comment accéder à une information de niveau secondaire. Par exemple, dans le cas d’un document HTML, le fragment permet d’indiquer l’idd’un élément dans la page vers lequel l’utilisateur veut naviguer. Par exemple :http://www.example.com/article.html#conclusionindique au navigateur qu’il lui faut afficher directement la section “conclusion” de la pagearticle.html.
Les exemples ci-dessous, extraits du RFC 3986, illustrent les différentes parties d’un URI :
foo://example.com:8042/over/there?name=ferret#nose
\_/ \______________/\_________/ \_________/ \__/
| | | | |
scheme authority path query fragment
| _____________________|__
/ \ / \
urn:example:animal:ferret:nose
Le premier exemple indique une ressource stockée sur le serveur example.com, accessible sur son numéro de port 8042 via le protocole foo. La ressource demandée est accessible via le chemin / la route /over/there, en spécifiant l’information name=ferret et en indiquant que l’utilisateur est intéressé par le fragment nose.
Le second exemple est de type nom (URN). Il ne contient que le schéma (urn) et le chemin d’accès (example:animal:ferret:nose)
Le language HTML
L’HyperText Markup Language (HTML) permet de définir le format des documents échangés sur le web. Il s’agit d’un langage de balisage (markup language), dans le sens où il intègre des annotations de formatage dans le document lui-même. LaTeX ou Markdown sont d’autres exemples de langages de balisage.
Les balises HTML sont des tags ouvrant et fermant délimités par les caractères <et >, donnant des indications sur le formatage ou la sémantique du texte inclus dans les balises.
Voici un exemple de document HTML :
<!DOCTYPE html>
<html>
<head>
<title>Titre du document</title>
</head>
<body>
<h1>Titre de section 1</h1>
<p>Paragraphe de texte, faisant référence à une <a href="https://www.somewhere.out/page.html">ressource externe</a></p>
</body>
</html>
Le HTML permet de faire des références vers d’autres ressources web, grâce aux liens hypertexte identifiés par la balise <a href="URI de la ressource">Nom du lien</a>.
Le protocole HTTP
Le troisième élément constitutif du World Wide Web est le protocole HyperText Transport Protocol. Il s’agit d’un protocole basé sur des échanges textuels, fonctionnant en mode client/serveur par dessus le protocole TCP, qui lui fournit un transport fiable en mode flux d’octets. Le protocole HTTP utilise le port TCP 80 par défaut, tandis que sa version sécurisée par encapsulation TLS utilise le port TCP 443.
Le document standardisant le protocole HTTP dans sa version 1.1 est actuellement le RFC 3112
Format des messages
Les messages sont de deux types :
- des requêtes, envoyées par le client au serveur
- des réponses, envoyées par le serveur au client suite à une requête de ce dernier.
Requêtes
Une requête HTTP contient trois éléments :
- Une première ligne contenant :
- La méthode, spécifiant le type de requête (GET, PUT, POST, …)
- l’URI du document demandé
- La version d’HTTP utilisée par le client
- Un en-tête, contenant des paramètres optionnels à la requête (à partir de la version 1.1 d’HTTP, le champ d’en-tête “Host” est cependant obligatoire) . Chaque champ d’en-tête contient un nom et une valeur, et se termine par un retour à la ligne. L’en-tête se termine par une ligne vide.
- Un document MIMEfacultatif attaché à la requête.
Méthodes
Les méthodes HTTP permettent de préciser le type d’action à appliquer à la ressource. On parle parfois de “verbe” http en parlant de ces méthodes. La méthode “GET” est la plus connue, et sert à simplement demander la ressource souhaitée. La méthode “POST” permet quant à elle l’envoi d’information à un serveur distant. Il en existe cependant d’autres :
- PUT permet la mise à jour d’une ressource
- DELETE demande la suppression d’une ressource
- HEAD demande des informations concernant la ressources (métadonnées par exemple), sans pour autant transférer la ressource elle-même. Cela permet par exemple de vérifier l’existence d’un document, ou sa date de dernière modification.
- etc.
Champs d’en-tête
Les types de champ d’en-tête contenus dans les requêtes et les réponses HTTP sont nombreux. Dans le cas d’une requête, on trouvera notamment les champs suivant :
- Host : Le champ Host donne le nom DNS (FQDN) du serveur que l’on souhaite contacter. En effet, l’URI du document dans la première ligne de la requête ne contient en général que la partie “path”, sans indication explicite du serveur contacté. Le champ Host est donc particulièrement utile lorsqu’un serveur possède plusieurs noms DNS et/ou héberge plusieurs sites, afin que ce dernier puisse adapter le contenu en fonction du nom d’hôte utilisé.
- If-modified-since : Permet à un client de demander l’envoi d’une ressource uniquement si elle a été modifiée depuis une visite précédente ayant mené à une mise en cache. Ainsi, la page ne sera transférée que si elle diffère de celle présente dans le cache du client.
- Referrer : URI du document contenant le lien hypertexte ayant mené à cette requête.
On trouve également des champs donnant des informations sur la ressource ou le document concerné par l’échange. Il s’agit des champs MIME :
- Content-Length : longueur en octets du document
- Content-Type : indique le type MIME du document. Pour un document HMTL il s’agira de
text/html - Content-Encoding : Indique si le document a été encodé, par exemple via un algorithme de compression. Pour un encodage par le logiciel gzip, la valeur du champ vaudra
x-gzip
Réponses
Tout comme les requêtes, les réponses HTTP contiennent typiquement trois parties :
1) Une ligne contenant le statut de la réponse. Cette ligne commence par la version d’HTTP utilisée par le serveur, puis, séparée par un espace, le code de statut, et enfin, éventuellement, une explication textuelle de ce code.
2) Un en-tête similaire à celui de la requête, également terminé par une ligne vide 3) Un document MIME le cas échéant, représentant la ressource visée par la requête.
Les codes de statut sont composés de trois chiffres, dont le premier identifie le type de statut :
| Code | Signification |
|---|---|
| 1xx | Informatif |
| 2xx | Succès |
| 3xx | Redirection |
| 4xx | Erreur côté client |
| 5xx | Erreur côté serveur |
Il existe de nombreux codes HTTP, décrits dans la section 15 du RFC 9119 définissant la sémantique HTTP, à savoir la terminologie et les éléments indépendants de la version du protocole. En voici un échantillon :
- 101 Switching Protocols : Indique qu’un serveur accepte un changement de version HTTP sur cette connexion
- 200 OK : Succès de la requête
- 201 Created : la requête a réussi et a résulté en la création d’une ou plusieurs nouvelles ressources.
- 301 Moved Permanently : Indique que la ressource demandée a changé d’URI. Cette réponse doit être accompagnée d’un champ “Location” indiquant la nouvelle URI.
- 400 Bad Request : Le serveur n’a pas traité la requête en raison d’une erreur de format de cette dernière.
- 401 Unauthorized : Le client ne peut pas obtenir la ressource car il ne dispose pas des autorisations nécessaires.
- 404 Not Found : C’est probablement le code HTTP le plus connu. Il indique que la ressource demandée n’a pas été trouvée à l’URI indiquée.
- 418 I’m a teapot : Code d’erreur hérité du protocole “HyperText Coffee Pot Control Protocol” RFC2324, proposé le 1er avril 1998. Il ne s’agit pas d’un code de statut HTTP standard (il ne figure pas dans le RFC9119), mais est néanmoins supporté par de nombreux navigateurs web.
- 500 Internal Server Error : Le serveur n’a pas été en mesure de répondre à la requête. C’est une situation qui se produit par exemple en cas d’erreur ou de bug lors de la génération de page dynamique.
Analyse d’un échange HTTP
Afin d’illustrer les concepts vus plus haut, nous allons analyser le trafic réseau échangé lors de la navigation vers le site http://neverssl.com. Ce site ne fonctionne en effet volontairement pas par dessus TLS (protocole HTTPS), ce qui permet de visualiser les échanges en clair.
Vue d’ensemble de la conversation HTTP
L’image ci-dessous illustre les trames capturées par Wireshark lors de la navigation vers le site NeverSSH, une fois appliqué le filtre http.
 On peut effectuer les observations suivantes :
On peut effectuer les observations suivantes :
- Le premier message affiché est une requête HTTP : on reconnaît la méthode GET. Cela nous permet d’identifier le client comme étant la machine d’IP
192.168.1.8, et le serveur34.223.124.45. - Le serveur écoute bien sur le port réservé à HTTP (80). Le client utilise le port éphémère 49707 pour cette première requête.
- La version d’HTTP utilisée est la version 1.1. Nous verrons plus loin que d’autres versions cohabitent.
- La première requête concerne le document à la racine du serveur (chemin
/), et résulte en une réponse 200 OK. - Une seconde requête découle de la première, portant sur la ressource
/online. Cette ressource n’est plus disponible sur le serveur puisqu’on reçoit une réponse 301 Moved Permanently. Pour cette requête, le client a ouvert une seconde connexion TCP, puisque le numéro de port utilisé est à présent le 49708. - Une troisième requête, toujours sur le même serveur, demande cette même ressource, cette fois avec l’URI
/online/(notez l’ajout du/final). La requête aboutit, avec un code 200. - Enfin, une quatrième requête demande l’icône du site (favicon), toujours sur la même seconde connexion TCP, et aboutit également à la réponse attendue.
Analyse détaillée du premier échange
Connexion TCP
Regardons à présent de plus près les détails du premier échange. Pour cela, on utilise le filtre isolant l’échange HTTP (commande “Follow HTTP Stream”) du premier message. Voici ce qui est obtenu :
 Cette fois, le filtre appliqué ne se limite plus aux messages HTTP, et on voit figurer l’échange TCP sous-jacent à l’échange HTTP. En effet, comme mentionné en début de chapitre, HTTP utilise le protocole transport TCP. Avant l’envoi du message de requête HTTP, il faut donc ouvrir la connexion TCP avec le serveur visé. On aperçoit en effet ici le traditionnel “Three Way Handshake” de l’ouverture de connexion TCP dans les trois premiers messages affichés.
Cette fois, le filtre appliqué ne se limite plus aux messages HTTP, et on voit figurer l’échange TCP sous-jacent à l’échange HTTP. En effet, comme mentionné en début de chapitre, HTTP utilise le protocole transport TCP. Avant l’envoi du message de requête HTTP, il faut donc ouvrir la connexion TCP avec le serveur visé. On aperçoit en effet ici le traditionnel “Three Way Handshake” de l’ouverture de connexion TCP dans les trois premiers messages affichés.
Le quatrième message, qui est le premier contenant des données applicatives, correspond à l’envoi de la requête GET par le client.
Dans le cinquième message, le serveur accuse réception du segment TCP de la requête. Notons que ce segment ne contient pas de données HTTP : la longueur de son payload est nulle. Le sixième et le septième message contiennent, eux, les données applicatives de la réponse HTTP.
Et enfin, le dernier message est l’accusé de réception TCP par le client, validant la réception de la réponse HTTP.
Le schéma ci-dessous, produit par Wireshark grâce à l’outil “Flow Chart”, constitue une autre représentation de cet échange TCP.

Contenu HTTP
Lors de l’application de l’outil “Follow HTTP Stream”, une fenêtre “Pop Up” nous a permis de récupérer le contenu applicatif HTTP :
GET / HTTP/1.1
Host: neverssl.com
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Safari/605.1.15
Accept-Language: fr-FR,fr;q=0.9
Accept-Encoding: gzip, deflate
Connection: keep-alive
On y retrouve bien :
- La ligne de requête indiquant la demande (méthode GET) de la ressource à la racine (
/), avec le protocole HTTP version 1.1. - Le champ Host précise que le site consulté est situé sur l’hôte
neverssl.com - Le champ Accept indique les types de documents acceptés par le client (navigateur)
- Le champ User-Agent indique la version du logiciel client utilisé
- Accept-Language et Accept-Encoding indiquent les formats et le langage supportés
- Le champ Connection: Keep-alive demande que la connexion TCP reste ouverte après le traitement de la requête, au cas où le client souhaite en effectuer d’autres. De fait, la connexion TCP analysée plus tôt n’a pas été terminée (pas de segment FIN).
La réponse HTTP, quant à elle, contenait entre autres les lignes suivantes :
HTTP/1.1 200 OK
Date: Sun, 26 Nov 2023 20:38:03 GMT
Server: Apache/2.4.57 ()
Last-Modified: Wed, 29 Jun 2022 00:23:33 GMT
Content-Encoding: gzip
Content-Length: 1900
Content-Type: text/html; charset=UTF-8
<html>
<head>
<title>NeverSSL - Connecting ... </title>
<style>
[...]
La première ligne est bien la ligne de statut, avec le code 200. Les autres champs donnent le timestamp de la réponse, la version du logiciel serveur, la date de dernière modification de la ressources, et les informations MIME sur le document : il s’agit d’une page HTML compressée.
En plus de ces informations textuelles, Wireshark offre également une vision sur le document envoyé par le serveur. Seules quelques lignes ont été reproduites ici, mais on peut néanmoins noter :
- La ligne vide entre l’en-tête et le document, qui fait office de séparateur
- Le format HTML du document. Le document a été échangé sous forme compressée, comme l’indique le champ
Content-Encoding, mais Wireshark a effectué la décompression avant de l’afficher iciDeuxième demande et redirection
GET /online HTTP/1.1
Host: oldsplendidmajesticspell.neverssl.com
Connection: keep-alive
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Safari/605.1.15
Referer: http://neverssl.com/
Accept-Language: fr-FR,fr;q=0.9
Accept-Encoding: gzip, deflate
HTTP/1.1 301 Moved Permanently
Date: Sun, 26 Nov 2023 20:38:04 GMT
Server: Apache/2.4.57 ()
Location: http://oldsplendidmajesticspell.neverssl.com/online/
Content-Length: 260
Connection: Keep-Alive
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="http://oldsplendidmajesticspell.neverssl.com/online/">here</a>.</p>
</body></html>
L’échange HTTP ci-dessus montre la demande du client concernant la ressource /online. Cette demande est issue d’un lien hypertexte contenu dans le document d’URI http://neverssl.com/, comme l’indique le champ d’en-tête Referer.
Cette fois, au lieu de répondre par un code 200, le serveur répond en indiquant que la ressource demandée a changé d’URI : il utilise le code 301 Moved Permanently, fournit un champ Location avec la nouvelle URI, ainsi qu’une page HTML reprenant les informations de redirection.
Suite à cela, le client effectuera deux autres requêtes HTTP (pour /online/et /favicon.ico), qui se termineront par des réponses à code 200 OK, de manière similaire à la première requête.
Evolution d’HTTP
Source : Mozilla, guide HTTP, Evolution de HTTP
Version 0.9
La version initiale d’HTTP, proposée par Tim Berners-Lee dans le cadre de la mise en oeuvre du World Wide Web en 1989, n’avait pas de numéro de version mais fut ultérieurement référencée comme version 0.9. Cette version n’avait à l’époque que la méthode GET, et ne comprenait pas de champs d’en-tête. La réponse comportait uniquement un fichier HTML.
Version 1.0
La première évolution, HTTP/1.0, a étendu le protocole en ajoutant notamment d’autres méthodes, la ligne de statut pour la réponse, et les champs d’en-tête, permettant d’échanger d’autres formats de fichiers que le HTML. Cette version a fait l’objet d’un premier document à l’IETF en 1996, le RFC 1945. En pratique, cette version n’a pas vraiment été standardisée, mais s’est construite par les différentes expérimentations des acteurs. Elle souffrait donc de nombreux problèmes d’inter-opérabilité.
Version 1.1
Dès 1997, une version standardisée d’HTTP est apparue : la version HTTP/1.1. Cette version a introduit les améliorations suivantes :
- la ré-utilisation de la connexion TCP entre plusieurs requêtes d’un même client, afin d’économiser le temps d’ouverture et de fermeture de connexion (connexions persistantes)
- la possibilité de négocier le type de contenu (langage, encodage, type, …)
- la colocation de sites sur un même serveur grâce au champ Host, devenu obligatoire.
- le pipelining : la possibilité d’envoyer une seconde requête avant même d’avoir reçu l’entièreté de la réponse à la première. Bien que prometteur au départ, ce mécanisme souffre malheureusement de la contrainte de séquentialité : les réponses doivent être envoyées dans l’ordre de réception des requêtes correspondantes. Si la première requête nécessite un long temps de traitement, les suivantes sont retardées en conséquence. En pratique, le pipelining a été peu utilisé, et les serveurs web ont préféré ouvrir plusieurs connexions TCP en parallèle pour effectuer du multiplexage de requêtes.
Evolutions d’usage
La version 1.1. d’HTTP est restée très stable pendant deux décennies, grâce à son extensibilité (ajout de nouveaux champs d’en-têtes et de méthodes). Néanmoins, les usages et contextes d’utilisation d’HTTP ont évolués, en parallèle de la croissance d’Internet et de l’évolution des applications Web.
HTTPS
L’utilisation d’une couche de chiffrement en dessous d’HTTP date de 1994, lorsque Netscape Navigator a commencé à utiliser le protocole de chiffrement SSL par dessous HTTP. Actuellement, SSL a été remplacé par TLS, qui en est son évolution standardisée, et ce dernier est à présent devenu indispensable pour tout échange Web.
#TODO Schéma de la stack réseau IP/TCP/TLS/HTTP
WebDAV
Dès 1997, HTTP a été étendu pour permettre l’édition de document à distance. Cette version étendue de HTTP s’appelle WebDAV (Web-based Distributed Authoring and Versioning).
WebDAV permet :
- L’édition simultanée du contenu d’un dossier Web par plusieurs utilisateurs (auteurs) via un système de verrous
- La gestion des droits d’accès aux fichiers
- La gestion des versions des documents
WebDAV fonctionne notamment grâce à l’ajout de certaines méthodes au protocoles HTTP (COPY, LOCK, MOVE, …)
WebDAV a lui-même été étendu pour d’autres usages, comme par exemple le partage de calendrier avec CalDAV, la gestion de contact avec CardDAV ou encore la gestion de groupes avec GroupDAV.
API REST
Avec l’évolution des applications Web, un nouveau modèle d’usage a émergé : REST, ou Representational State Transfer. Dans ce mode d’utilisation du web, un serveur met un ensemble de ressources à disposition des clients via des URI pré-déterminées. L’utilisation des verbes HTTP classiques (GET, PUT, POST, DELETE, …) permet d’indiquer l’action souhaitée sur l’URI indiquée. Contrairement au WebDAV où le traitement est réalisé directement par le serveur de manière standard, chaque API REST nécessitent un code applicatif Web spécifique. Les API REST transmettent leurs informations sous divers format, dont le format JSON. Elles sont à présent omniprésentes sur le Web.
#TODO Créer une image sur cette base. 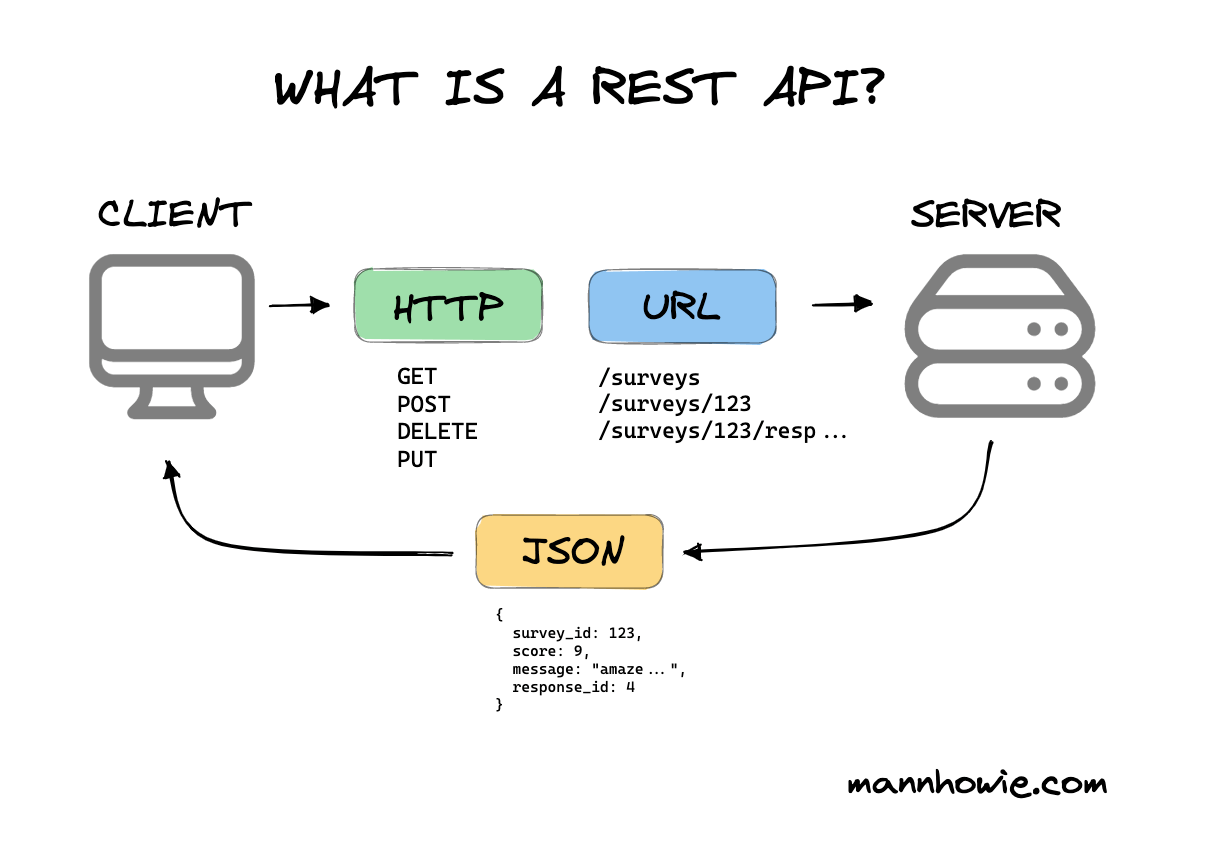
HTTP/2
Dans les années 2010, la complexité des pages Web a mis en lumière des problèmes de performances pour HTTP. L’amélioration de performance espérée par l’introduction du pipelining dans HTTP1.1. ne s’est pas concrétisé à cause de la contrainte de conservation de l’ordre des requêtes (HTTP Head of line Blocking), et est donc peu utilisé en pratique.
Google a proposé à l’époque le protocole expérimental SPDY, qui a éveillé l’intérêt, et a posé les base du protocole HTTP/2, standardisé en 2015.
Les spécificités de HTTP/2 sont les suivantes :
- Encodage en binaire, alors que les versions précédentes étaient encodées en format textuel.
- Multiplexage des requêtes, permettant la gestion de plusieurs requêtes en parallèle sans contrainte d’ordonnancement (cfr ci-dessous)
- Compression des en-têtes
- Possibilité pour le serveur d’envoyer des données au client avant que ce dernier ne le demande (SERVER PUSH). En pratique, cette extension n’a pas rempli ses promesses et son support n’est plus assuré par tous les navigateurs (ex : retrait de la fonctionnalité PUSH dans Chrome en 2022)
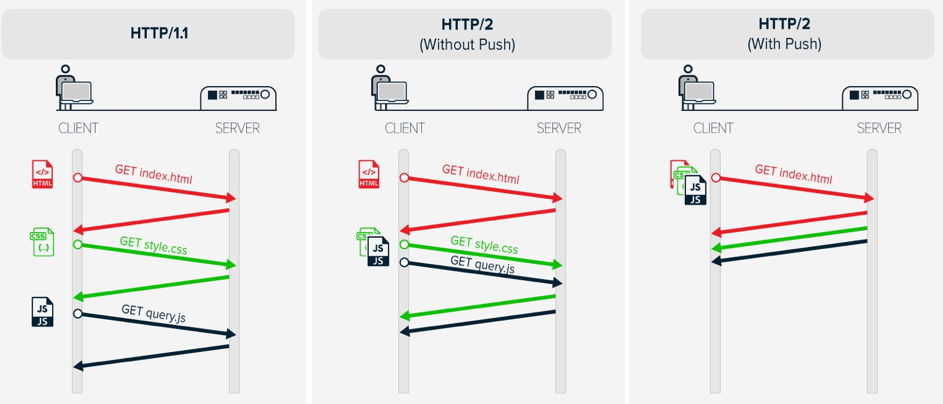
Josh Glasson explique le multiplexage introduit par HTTP/2 dans son article HTTP Pipelining et Multiplexing L’image ci-dessous, reprise de cet article, présente trois échanges : 1) Un échange en HTTP/1.0, où il faut attendre la réception complète de la réponse à une requête avant d’en envoyer une autre (+ ouverture/fermeture de connexion à chaque fois) 2) Un échange en HTTP/1.1, avec le pipelining : la seconde et la troisième requête sont envoyées à la suite, sans attendre de réponse. Néanmoins, comme la seconde requête nécessite un long temps de génération de réponse, la troisième est retardée d’autant. 3) Un échange en HTTP/2 (multiplexage): les réponses à la seconde et à la troisième requêtes sont traitées indépendamment l’une de l’autre. La troisième réponse est envoyée dès qu’elle est disponible, indépendamment de la seconde.

Quant à la fonctionnalité SERVER PUSH, elle peut, en théorie, réduire le temps d’obtention d’une page web en réduisant celle-ci jusqu’à un RTT. L’image ci-dessous, extraite de l’article # High Performance with HTTP / 2 PUSH, montre l’exemple d’un client demandant une page web index.html, page web qui référence deux ressources sur le même serveur : style.css et query.js.
- En HTTP/1.1 (sans pipelining), trois aller-retours (RTT) sont nécessaires pour obtenir l’ensemble des éléments de la page.
- En HTTP/2 sans PUSH, grâce au multiplexage, deux aller-retours suffisent : le client a pu demander au même moment les deux documents référencés par la page d’index.
- En HTTP/2 avec PUSH, le serveur peut, à la réception de la requête, anticiper le besoin des documents style.css et query.js et déjà les envoyer au client, réduisant ainsi la requête à un aller-retours.
HTTP/2 a été rapidement adopté grâce au fait qu’il ne nécessite aucune adaptation des contenus Web. Dès qu’un navigateur et un logiciel serveur le supportent, il peut être utilisé. Si ce n’est pas le cas, l’échange se basera simplement sur HTTP/1.1.
Quic et HTTP3
Référence : IONOS, HTTP/3 : présentation du nouveau Hypertext Transfer Protocol
Malgré l’introduction du multiplexage dans HTTP/2, les performances des serveurs web plafonnent. Une de ces raisons en est l’utilisation de TCP, et notamment le blocage du transfert d’information dès qu’un paquet est perdu, le temps de la mise en oeuvre du mécanisme de retransmission. Pour pallier ce problème, Google a développé un protocole permettant de garantir la fiabilité d’un transfert de données tout en étant plus performant que TCP. Ce protocole, appelé QUIC, tourne par dessus UDP. Cela permet d’éviter les établissements de connexion TCP(handshake) et le blocage des transferts lors des retransmissions.
En 2018, l’IETF, reconnaissant l’intérêt de l’utilisation d’HTTP par dessus QUIC, s’en est servi comme base pour une nouvelle version d’HTTP : HTTP/3. Cette version possède les caractéristiques suivantes :
- Utilisation par dessus UDP et QUIC, pour de meilleures performances
- Utilisation du TLS incluse dans QUIC, ce qui réduit encore le temps d’établissement de connexion.
- Connexion et transfert maintenus même en cas de changement de réseau
L’image ci-dessous, tirée de Wikipédia, montre les trois piles protocolaires des différentes versions d’HTTP. On observe la couche de chiffrement, par dessus TCP en HTTP/1.1 et HTTP/2, et intégrée à QUIC dans HTTP3. On constate également le basculement de TCP à UDP entre HTTP/2 et HTTP/3.

Les serveurs Web
Le World Wide Web est défini par un format de document, un système d’adressage et un protocole, mais pour qu’il puisse fonctionner, il faut des logiciels implémentant les deux rôles client et serveur.
Les navigateurs sont les logiciels côté client, et sont capable d’effectuer des requêtes HTTP, d’analyser les réponses et d’afficher pour l’utilisateur le contenu reçu sous forme de page web.
Côté serveur, différents logiciels se partagent le marché, depuis le premier serveur HTTPd (démon HTTP) du CERN. Historiquement, le serveur Apache est celui qui a dominé le web durant de nombreuses années. Il est à présent concurrencé entre autres par le serveur IIS de Microsoft et le serveur nginx. Les différents parts de marché détenues par chaque serveur Web sont monitorées notamment par Netcraft, qui publie régulièrement les résultats de ses études sur son blog
Pour implémenter un serveur Web basique, il faut lui fournir la capacité de :
- stocker des documents, par exemple dans un répertoire dédié
- recevoir une requête HTTP sur son port TCP 80 et/ou 443
- analyser cette requête et
- en déduire le document demandé, sur base de l’URI
- analyser les en-têtes
- préparer la réponse en fonction des informations ci-dessus, en récupérant ou générant le document correspondant à l’URI
- envoyer la réponse au client.
Depuis l’origine du web, ses usages ont évolués et les serveurs supportent à présent bon nombre de fonctionnalités supplémentaires, dont voici quelques exemples.
Applications dynamiques
A l’origine, le web était principalement “statique” : les documents étaient stockés sur le serveur, et ce dernier se contentait d’aller les chercher sur son système de fichiers. Pour enrichir ce comportement, des sites web dit dynamiques sont apparus : plutôt que de transférer des données statiques, ils ont commencé à générer du contenu en fonction du contexte de la requête. La page web n’existe donc pas telle qu’elle avant que le serveur ne reçoive de requête la concernant.
Voici ci-dessous un exemple très simple de site web dynamique (ou application web) en Node.js. Ici, le serveur web répond aux requêtes reçues sur son port TCP 80. Lorsqu’il reçoit une requête, il ne va pas chercher de fichier sur le système de fichiers, mais génère une page web “à la volée”, affichant l’adresse IP source de la requête.
Notez la création de la réponse en trois étapes :
- La définition du code de statut
- L’ajout d’en-tête
- L’envoi du document MIME (dont le content-type est défini dans l’en-tête, justement).
const http = require('http');
const host = '0.0.0.0';
const port = 80;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/html');
res.end(`<html><h1>Hello ${req.socket.remoteAddress}!</h1></html>`);
});
server.listen(port, host, () => {
console.log('Web server running at http://%s:%s',host,port );
});
Cet exemple est très simpliste, et en pratique, on utilisera souvent une base de données pour stocker les informations qui permettront de générer les pages web à la demande.
Par exemple, sur un site d’e-commerce, les informations de chaque compte client sont stockés sur une base de données, et lorsque le client souhaite visualiser ces informations, le serveur effectuera une requête SQL (ou non) sur la base de données pour les récupérer, générer la page web en incluant ces informations et renvoyer le document ainsi construit.
L’image ci-dessous montre un échange client/serveur dans lequel le serveur interroge une base de données pour pouvoir construire sa réponse.
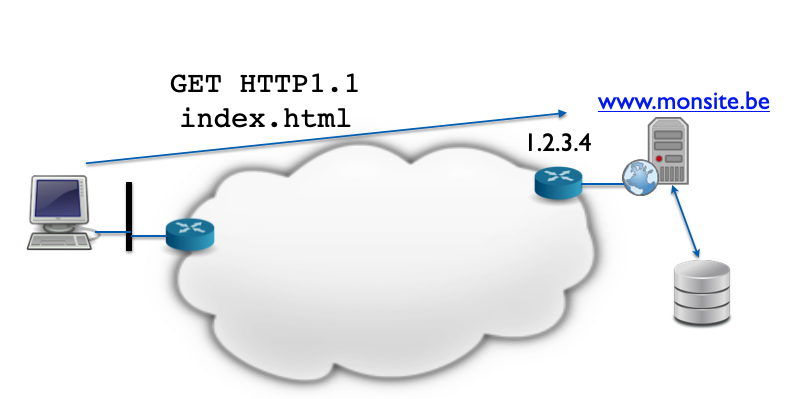
Chiffrement
Comme mentionné plus haut, afin de sécuriser les échanges Web, l’utilisation du protocole de chiffrement TLS est préconisé. Tout serveur Web moderne se doit donc d’implémenter HTTPS, afin de :
- être authentifié auprès du client grâce à un certificat
- chiffrer les communiations HTTP
Compression
Afin d’alléger la taille des informations échangés par dessus HTTP, il est possible de compresser les données envoyées/reçues. Pour supporter la compression, le serveur web doit disposer d’implémentation d’algorithmes de compression. Lors de la requête, le client indique dans son en-tête (champ Accept-Encoding) s’il supporte la compression, et les algorithmes accepté. Sur cette base, le serveur, une fois le document récupéré ou généré, pourra le compresser avant l’envoi.
Authentification
Les serveurs peuvent éventuellement implémenter des systèmes d’authentification afin que les clients puissent accéder à certaines ressources à accès contrôler, ou à du contenu individualisé.
Pour maintenir une session authentifiée, des cookies seront souvent utilisés : il s’agit d’une petite quantité d’information envoyée par le serveur au client, via l’en-tête de sa réponse (Set-Cookie: nom=valeur). Le client stocke cette information, et la joindra à l’en-tête de toutes ses requêtes ultérieures (Cookie: nom=valeur).
La problématique de l’authentification Web et l’utilisation des cookies est complexe, et l’implémentation d’un mécanisme d’authentification réellement sécurisé nécessite une bonne connaissance du problème et l’utilisation des outils et paramètres appropriés.
Virtual Hosting
Le Virtual Hosting est une pratique consistant à héberger plusieurs sites sur un même serveur. Cette pratique est notamment utilisée par les hébergeurs Web pratiquant l’hébergement mutualisé : ils “partagent” un serveur physique entre plusieurs sites de leurs clients.
Lorsqu’un tel serveur web reçoit une requête, il doit donc pouvoir décider quel site est associé à cette requête, pour pouvoir y apporter la réponse adéquate.
Il existe trois possibilités :
- Le Virtual Hosting par IP : Si le serveur possède plusieurs adresses IPs, il peut associer chaque IP à un site web. Il se basera donc sur l’adresse IP de destination de la requête pour connaitre le site concerné. L’inconvénient de ce mécanisme est qu’il faut disposer d’une adresse pour chaque site.
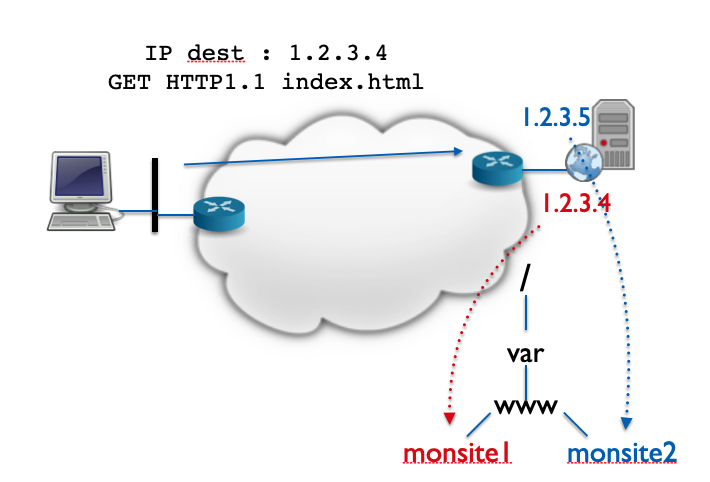
- Le Virtual Hosting par port : En associant un site à un numéro de port TCP, on peut également effectuer du Virtual Hosting. Dans ce cas, le serveur se basera sur le numéro de port destination de la requête pour connaître le site concerné. L’inconvénient de ce système est que les sites seront donc, sauf un, associés à des numéros de port TCP différents du port Web classique (80/443). L’utilisateur devra spécifier explicitement cette information dans l’URI du document demandé.
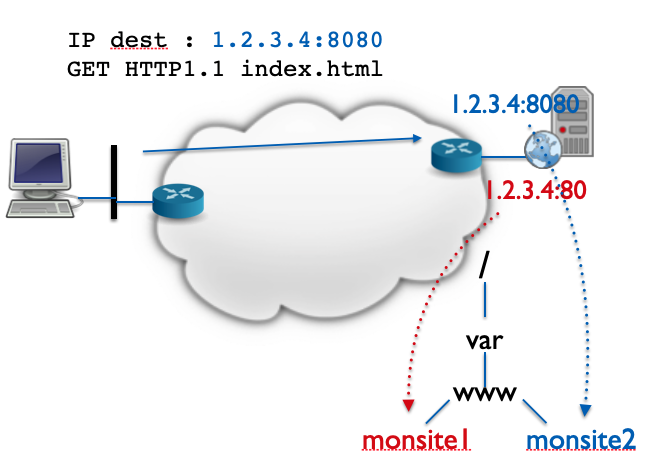
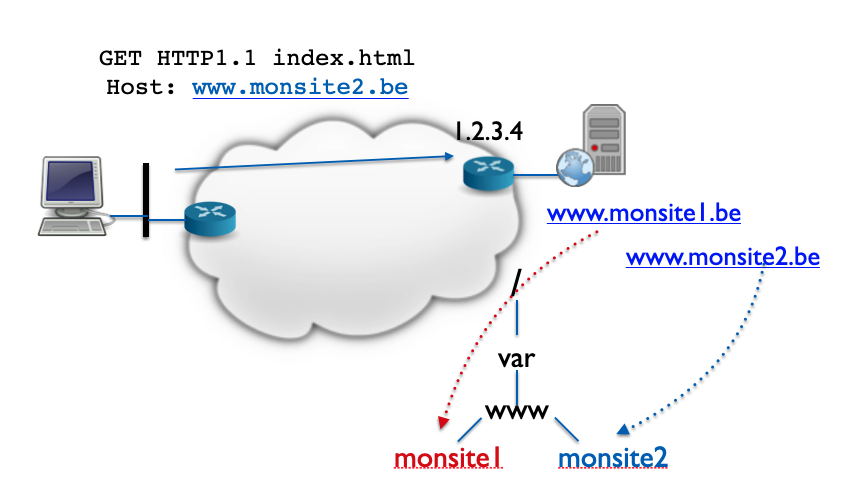
- Le Virtual Hosting par nom : cette troisième technique est plus souple que les deux autres car elle ne nécessite ni adresse IP ni numéro de port supplémentaire. Elle s’applique lorsque les sites possèdent des noms d’hôtes différents, associés à une même adresse IP dans le DNS. Comme le nom d’hôte du site souhaité doit obligatoirement être indiqué dans les en-têtes HTTP depuis HTTP/1.1, le serveur peut se baser sur cette information pour connaitre le site concerné par la requête.
Configuration du Virtual Hosting sur Apache
Apache est un logiciel serveur Web largement utilisé sur Internet depuis de nombreuses années, qui tourne notamment par dessus l’OS Linux.
Voici ci-dessous un petit exemple de configuration Apache permettant d’héberger deux sites Web en Virtual Hosting par nom.
Listen 80
<VirtualHost *:80>
DocumentRoot "/www/example1"
ServerName www.example1.com
# Autres directives ici
</VirtualHost>
<VirtualHost *:80>
DocumentRoot "/www/example2"
ServerName www.example2.com
# Autres directives ici
</VirtualHost>
Cette configuration permet d’avoir deux sites web hébergés sur le même serveur, en utilisant une adresse IP unique, et l’unique port TCP 80. Pour que cela fonctionne, il faut que les deux noms d’hôte www.example1.com et www.example2.com possèdent tous les deux un Resource Record A pointant vers l’IP du serveur.
On voit apparaitre dans cet exemple de configuration une unique directive générale : Listen 80, qui précise à Apache le numéro de port TCP sur lequel il doit se mettre à l’écoute.
Ensuite, deux sections sont indiquées, délimitées par des tags semblables aux tags HTML. Il s’agit de section de type “Virtual Host”, définissant un comportement propre à chaque site / Virtual Host. Dans chaque section, on trouve les deux directives suivantes :
DocumentRoot: Indique le répertoire contenant les fichiers (HTML ou autres) du site Web concernéServerName: Indique le nom d’hôte correspondant au Virtual Host. Apache scannera les champs Host des requêtes reçues et identifiera la section<Virtual Host>à considérer sur base de la valeur de ce champ et de la directiveServerNamede la section.